如何下载python动态网站成品
在当今数字化时代,动态网站已成为信息传播和交互的重要平台。有时我们可能需要获取动态网站的成品进行分析、学习或其他用途,而python为我们提供了一些有效的方法来实现这一目标。
一、了解动态网站
动态网站与静态网站不同,它的内容是根据用户请求或其他条件实时生成的。常见的动态网站技术包括php、asp.net、python(如django、flask)等。在下载动态网站成品时,我们需要考虑如何捕捉并保存这些动态生成的内容。
二、使用requests库
python的requests库是一个常用的http库,它可以方便地发送http请求并获取响应。对于一些简单的动态网站,我们可以通过模拟浏览器请求来获取页面内容。例如:
```python
import requests
url = ⁄'目标动态网站地址⁄'

response = requests.get(url)
if response.status_code == 200:
with open(⁄'网站成品.html⁄', ⁄'w⁄', encoding=⁄'utf-8⁄') as file:
file.write(response.text)
```
三、处理javascript渲染
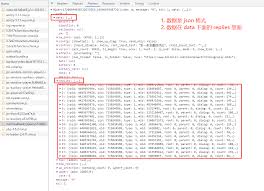
很多动态网站的内容是通过javascript渲染生成的,直接使用requests库获取到的可能只是初始的html框架,缺少实际渲染后的内容。这时我们可以借助selenium库。selenium可以控制真实的浏览器,模拟用户操作,等待页面完全渲染后再获取页面内容。
```python
from selenium import webdriver
driver = webdriver.chrome()
driver.get(⁄'目标动态网站地址⁄')
page_source = driver.page_source
driver.quit()
with open(⁄'网站成品.html⁄', ⁄'w⁄', encoding=⁄'utf-8⁄') as file:
file.write(page_source)
```
四、保存相关资源
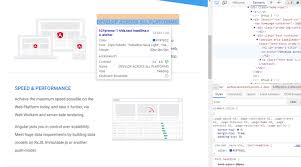
动态网站通常还包含图片、脚本、样式表等资源。在下载网站成品时,我们需要确保这些资源也被正确保存。可以通过解析获取到的html内容,提取资源链接,然后使用requests库下载并保存这些资源到本地指定目录。
总之,利用python的相关库和方法,我们能够有效地下载动态网站成品,无论是简单的通过requests库直接获取,还是借助selenium处理javascript渲染,都能满足不同动态网站的下载需求,为我们进一步学习和研究提供便利。








